Transformer(Attention机制)论文阅读-2
结构
编码器encoder
包含了6个相同的层组成的“stack”,每层两个子层,一个是多头自注意力机制,一个是“simple, positionwise fully connected feed-forward network”简单的、互联的前馈网络。
在每子层的周围使用残差连接、层归一化。“We employ a residual connection around each of the two sub-layers, followed by layer normalization.”,也就是每层的输出为 LayerNorm(x + Sublayer(x))。
所有层被标准化为512维的输出。
解码器decoder
同样包含了6个相同的层组成的“stack”,但每层三个子层,一个是多头自注意力机制,一个是多头编码器-解码器注意力机制,“performs multi-head attention over the output of the encoder stack”,一个是简单的、互联的前馈网络。
其中的自注意力层和编码器有所不同,不会关注当前位置后面的位置。
和编码器相同,在每子层的周围使用残差连接、层归一化。“We employ a residual connection around each of the two sub-layers, followed by layer normalization.”,也就是每层的输出为 LayerNorm(x + Sublayer(x))。所有层被标准化为512维的输出。
注意力机制
本质是将查询(query)和一组键值对(a set of key-value pairs,是键和值)映射到输出。
换言之,这个键和这个值是配对的,查询是额外的。
输出是值的加权和,权重由查询和对应关键字兼容性函数确定。(weight assigned to each value is computed by a compatibility function of the query with the corresponding key.)
将三种向量各自组成查询(Q),键(K),值(V),然后三个矩阵变一个Output。
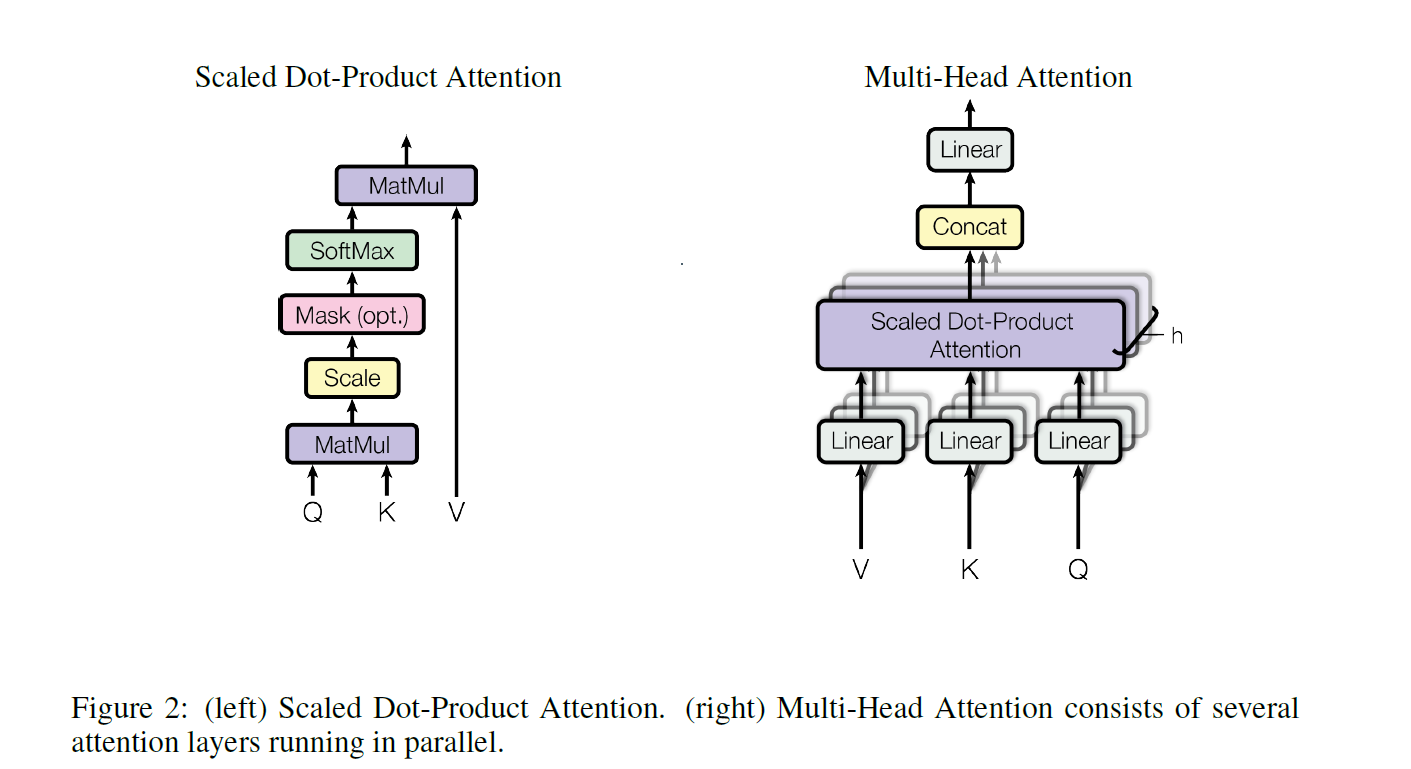
其中,求权重的“Scaled Dot-Product Attention”的公式为:

即计算QKV三者输出。假设Q和K等长,长度dk,V长度dv,计算过程:
- 求QK余弦相似度:求夹角余弦值,相当于判断向量夹角,角度越小越相似。
- 余弦相似度除(dk)^(1/2)(长度)
- softmax得到权重,即是attention。
- attention权重和V相乘,每一行就是需要的输出。
Scaled Dot-Product Attention属于点乘注意力机制,并在一般点乘注意力机制的基础上,加上了scaled。scaled是指对注意力权重进行缩放,以确保数值的稳定性。
常用注意力机制有additive attention、dot-product (multiplicative) attention,加性注意力和点积注意力。Scaled Dot-Product Attention属于点积注意力,但Scaled Dot-Product Attention 比传统的点积注意力多了一个根号dk的部分。
加性注意力使用具有单个隐藏层的前馈网络来计算兼容性函数。
虽然加与乘注意力两者在理论复杂性上相似,但点积注意力在实践中要快得多,而且更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
引入根号dk的原因:弥补点积注意力相对于加法注意力的缺陷:对于较大的dk值,点积的大小会变大,从而将softmax函数推向具有极小梯度的区域。根号dk可以抵消这个影响。
多头注意力
从“performing a single attention function with dmodel-dimensional keys, values and queries”
到“linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively,On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values. These are concatenated and once again projected, resulting in the final values.”
(projected,含预计和投影的意思。)
翻译一下就是,本来是单头注意力,只有一个注意力函数。
而多头注意力是用不同的、通过机器学习学到的线性投影,将查询、键和值(三个向量)分别线性投影到dk、dk和dv维度h次,也就是h个注意力头。然后在查询、键和值的每个投影版本上,我们并行执行注意力函数,生成dv维输出值。这些被连接起来,组成多头,并再次投影,得到最终值。
多头注意力允许模型联合关注来自不同位置的不同表示子空间的信息。对于一个单一的注意力头而言,做不到,因为单头注意力使用的平均会抑制这种情况。
“头”指的是某次线性投影得到的注意力。

团队在测试的时候使用了八个头,h=8,QK长度均为64,d(model)则是h与64相乘。
总计算成本比较低,因为每个头的维数并不高,而且还可以并行计算。
Transformer中注意力机制的使用
编码器-解码器注意力
在解码器中使用。
查询来自上一个解码器层,键和值来自编码器的输出。
这种机制模仿了序列到序列模型中的典型编码器-解码器注意力机制,允许解码器中的每一个位置关注输入序列中的所有位置。
编码器自注意力
所有的键、值和查询都来自同一个地方,也就是是编码器中前一层的输出。
这种机制允许编码器中的每个位置关注编码器的前一层中的所有位置。
解码器自注意力
基本同编码器,但是解码器只能关注半边的信息,“prevent leftward information flow in the decoder to preserve the auto-regressive property”
位置前馈网络Position-wise Feed-Forward Networks
每层都包含一个全连接神经网络。“applied to each position separately and identically”,分别且相同地应用于每个位置。
这个网络包含了两个线性变换,一个是relu激活。
不同层网络结构相同但参数不同。
这个网络也可以看作是一个卷积核大小为1的两个卷积。实验者设置的输入和输出的维度为dmodel=512,内层的维度为dff=2048。
Embeddings and Softmax
embedding含义为嵌入层,可以把信息选择性保留,缩小矩阵大小(稀疏矩阵)抽象但更容易处理,即降维;也可以升维。
transformer中的embedding是输入token和输出token转换为维度为dmodel的向量,还使用普通线性变换和softmax函数,将解码器的输出转换为预测的下一个token概率。
transformer中两个嵌入层和预softmax线性变换之间共享相同的权重矩阵。在embedding层中,将这些权重和根号dmodel相乘。
位置编码positional encodings
只用注意力机制,不使用卷积和递归,因此需要引入相关位置信息,计算序列中的token。
每层的复杂度、顺序操作、最大路径长度

n是序列长度,d是表示维度,k是卷积的核大小,r是限制自注意中邻域的大小。
transformer将位置编码和“编码器和解码器堆栈底部的‘输入embedding’”结合。(指编码器解码器都有多层,这里是加到最底下一层的embedding子层)
位置编码与embedding具有相同的维度dmodel,因此可以将两者进行直接处理。有多种位置编码可以选择,可以选择让机器学习编码,也可以直接使用固定方式。而本文使用的是不同频率正余弦函数。
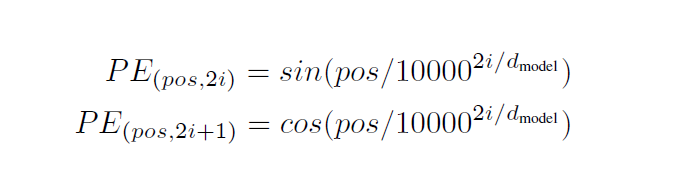
输入参数中,pos是位置,i是尺寸。
可以理解为将每个位置和频域上的冲激相对应起来。之所以选择正余弦函数,是对pos的任何偏移,都可以将函数转化为没有偏移的正余弦函数。
自注意力机制和递归、卷积对比
三个方面:
每层的总计算复杂度
可以并行化的计算量
网络中长程依赖项之间的路径长度(path length between long-range dependencies in the network)
网络需要学习长程依赖关系,而影响学习这种依赖性的能力的一个关键因素是前向和后向信号在网络中必须经过的路径的长度,越短就越容易学习。
研究时统计了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度:
每层的复杂度、顺序操作、最大路径长度
n是序列长度,d是表示维度,k是卷积的核大小,r是限制自注意中邻域的大小。
1 | |
自注意力层:通过恒定数量的顺序执行操作连接所有位置
递归层:需要O(n)个顺序操作
当序列长度n小于表示维度d时,自注意层比递归层更快
为了提高涉及非常长序列的任务的计算性能,可以将自注意限制为仅考虑输入序列中以相应输出位置为中心的大小为r的邻域。这将使最大路径长度增加到O(n=r)。我们计划在未来的工作中进一步研究这种方法。
核宽度k<n的单个卷积层并不连接所有输入和输出位置对。在连续核的情况下,这样做需要O(n=k)个卷积层的堆栈,或者在扩张卷积的情况下需要O(logk(n))[18],从而增加网络中任意两个位置之间最长路径的长度。卷积层通常比递归层贵k倍。然而,可分离卷积[6]将复杂性显著降低到O(k n d+n d2)。然而,即使k=n,可分离卷积的复杂性也等于自注意层和逐点前馈层的组合,这是我们在模型中采用的方法。
另外,自注意力可以产生更多可解释的模型。
我们从我们的模型中检查注意力分布,并在附录中给出和讨论示例。单个的注意力头不仅清楚地学会了执行不同的任务,而且许多注意力头似乎表现出与句子的句法和语义结构有关的行为。
训练
使用BLEU评价效果。